









Découvrez le dernier avancement en matière d’intelligence artificielle avec le lancement de Gemini 2.5 Flash par Google. Ce modèle innovant intègre des capacités de raisonnement améliorées, permettant aux développeurs de gérer les coûts et la qualité des réponses en fonction des besoins. Explorez ces caractéristiques révolutionnaires qui redéfinissent l’interaction homme-machine.
Google a lancé la version préliminaire de Gemini 2.5 Flash. Ce modèle est conçu pour offrir aux développeurs une plus grande flexibilité en leur permettant de contrôler le niveau de raisonnement en fonction du prompt et de l’utilisation prévue. Ce « budget de raisonnement » permet de gérer combien de raisonnement est effectué pour répondre à des requêtes complexes.
Tous les modèles de la famille Gemini 2.5 possèdent désormais des fonctionnalités de raisonnement permettant au modèle de réfléchir avant de répondre, garantissant ainsi une performance améliorée et une plus grande précision. Cela s’avère particulièrement utile pour des requêtes nécessitant un raisonnement multi-étapes, telles que des problèmes mathématiques ou l’analyse de questions de recherche.
Au lieu de générer immédiatement une sortie, le modèle peut effectuer un processus de « réflexion » pour mieux comprendre la question, décomposer des tâches complexes et planifier sa réponse.
Pour les développeurs
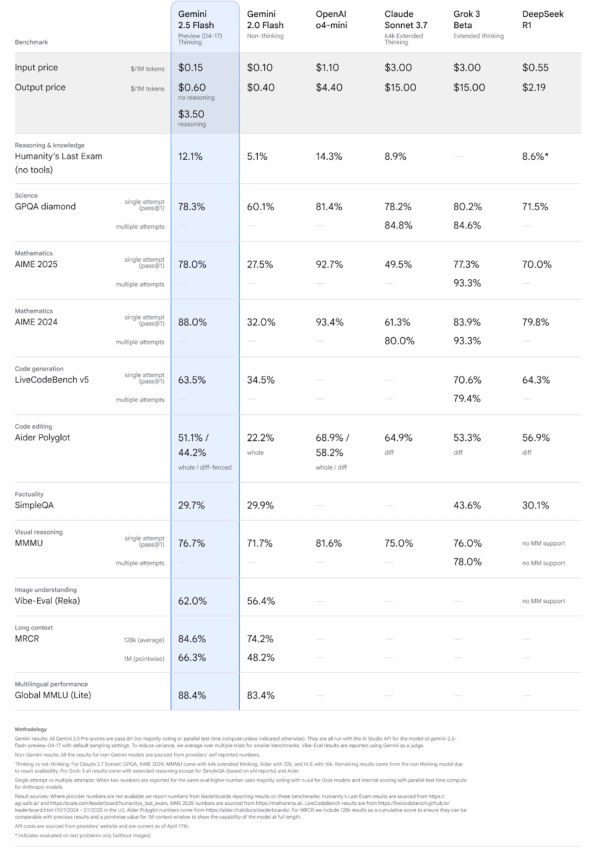
Les modèles Flash de Gemini sont reconnus pour leur rapidité et leur coût réduit, des caractéristiques qu’ils conservent avec la version 2.5 Flash. Google introduit toutefois des capacités de raisonnement où les développeurs peuvent « définir des budgets de raisonnement pour équilibrer coût et qualité ». Voici quelques spécifications clés pour Gemini 2.5 Flash en prévisualisation :
- Limites de taux : 1000 RPM / 10,000 RPD (niveau payant), 10 RPM / 500 RPD (niveau gratuit)
- Date de coupure des connaissances : janvier 2025
- Modalités d’entrée : texte, images, vidéo, audio
- Modalités de sortie : texte
- Fenêtre de contexte : 1 million de tokens
- Longueur de sortie maximale : 64K tokens
Les développeurs peuvent contrôler « le nombre de tokens qu’un modèle peut générer tout en réfléchissant », avec des réglages allant de 0 à 24,576 tokens. Cette fonctionnalité est accessible via un curseur dans Google AI Studio et Vertex AI, ainsi qu’en tant que paramètre API. Les graphiques fournis démontrent comment la qualité du raisonnement s’améliore avec l’augmentation du budget. Si le budget de raisonnement est réglé à zéro, le nouveau modèle égalera le coût et la latence de la version 2.0 Flash.
Si aucun budget n’est spécifié, Gemini 2.5 Flash « décide automatiquement combien réfléchir en fonction de la complexité de la tâche perçue ». Google a fourni des exemples de raisonnement minimal, moyen et élevé :
Exemples de prompts avec un raisonnement minimal :
- « Merci » en espagnol
- Combien de provinces le Canada a-t-il ?
Exemples de prompts avec un raisonnement moyen :
- Vous lancez deux dés. Quelle est la probabilité qu’ils totalisent 7 ?
- Ma salle de gym a des heures de jeu au basketball de 9h à 15h les lundi, mercredi et vendredi, et de 14h à 20h les mardi et samedi. Si je travaille de 9h à 18h cinq jours par semaine et que je souhaite jouer cinq heures au basketball pendant la semaine, créez un emploi du temps qui me permettra de tout concilier.
Exemples de prompts avec un raisonnement élevé :
Dans le contexte des agents, une autre illustration est que des résumés rapides impliqueraient un budget de réflexion faible, tandis qu’une analyse détaillée exigerait un budget plus élevé.
Gemini 2.5 Flash est maintenant accessible en prévisualisation pour les développeurs via Google AI Studio et Vertex AI. Google a aussi annoncé qu’il continuera à améliorer Gemini 2.5 Flash, avec de nouvelles fonctionnalités à venir avant qu’il ne soit disponible pour un usage général en production.
Application Gemini
La version 2.5 Flash (expérimentale) sera également intégrée dans l’application Gemini, permettant d’ajuster automatiquement le niveau de raisonnement en fonction de la complexité du prompt. Les utilisateurs finaux ne bénéficieront cependant d’aucun ajustement manuel dans l’application.
Au lancement, les différentes fonctionnalités de l’application Gemini, telles que les applications/extensions, le téléversement de fichiers, etc., seront prises en charge. Ce modèle remplacera 2.0 Flash Thinking (expérimental), qui a été mis à jour pour la dernière fois en mars.
Mon avis :
La version preview de Gemini 2.5 Flash introduit une nouvelle fonctionnalité de contrôle des budgets de réflexion, permettant aux développeurs d’équilibrer coût et qualité de réponse. Malgré sa rapidité et sa flexibilité, cette approche peut engendrer des réponses variables en fonction des complexités des requêtes, ce qui pourrait nécessiter des ajustements pour optimiser l’expérience utilisateur.
Les questions fréquentes
Quelle est la principale nouveauté de Gemini 2.5 Flash ?
Google a lancé Gemini 2.5 Flash avec des capacités de raisonnement permettant aux développeurs de contrôler le niveau de raisonnement en fonction de l’invite et du cas d’utilisation. Cela inclut la possibilité d’établir un "budget de réflexion" qui détermine combien de raisonnement est effectué avant de répondre.
Comment les modèles Gemini 2.5 améliorent-ils les performances par rapport aux versions précédentes ?
Les modèles de la famille Gemini 2.5 sont conçus pour réfléchir avant de répondre, ce qui améliore la précision et la performance lors de la gestion de requêtes complexes qui nécessitent un raisonnement en plusieurs étapes, comme des problèmes de mathématiques ou des analyses de questions de recherche.
Quelle est la configuration des limites d’utilisation pour Gemini 2.5 Flash ?
Les limites de taux pour la version payante de Gemini 2.5 Flash sont de 1000 RPM et 10 000 RPD, tandis que pour la version gratuite, elles sont de 10 RPM et 500 RPD. Le modèle prend également en entrée des modalités variées telles que du texte, des images, de la vidéo et de l’audio, avec une fenêtre de contexte allant jusqu’à 1 million de tokens.
Comment les développeurs peuvent-ils ajuster le budget de pensée dans Gemini 2.5 Flash ?
Les développeurs peuvent contrôler le nombre de tokens générés lors du processus de réflexion avec un budget allant de 0 à 24 576 tokens. Ce budget peut être ajusté via un curseur dans Google AI Studio et Vertex AI, permettant d’optimiser le coût par rapport à la qualité, ce qui est essentiel dans des applications nécessitant différentes intensités de raisonnement.






